
OISA设计原则
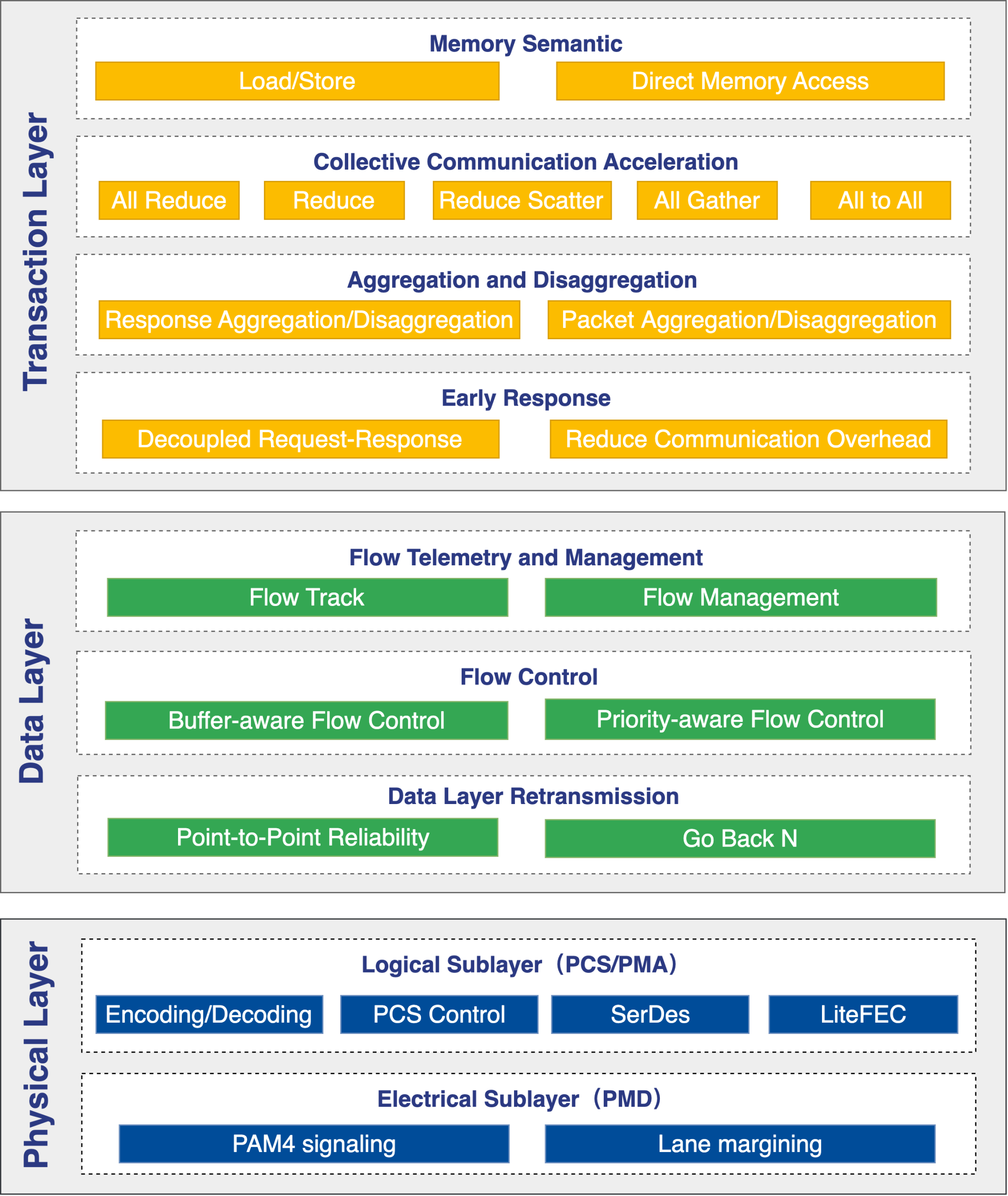
多模内存访问
OISA支持多种内存访问模式,以满足不同应用场景需求:
OISA Load/Store:指令直驱模式专为细粒度、低延迟的数据访问设计,适用于需要快速响应的短报文传输。
OISA Direct Memory Access:直接内存访问模式擅长粗粒度、高吞吐量的批量数据传输,适用于AI芯片间大数据块的搬运。
集合通信加速
OISA集合通信加速将传统由AI芯片执行的集合通信操作卸载到交换芯片,使其从被动转发设备转变为中间计算节点,以降低交换数据量,从而提升效率。针对不同的通信原语进行定制化加速,确保在大规模AI任务中实现最优性能。
聚合与分解
OISA支持报文聚合与分解机制,机会性将多个短报文合并成一个长报文传输,以提升载荷率。该功能解决短报文多导致带宽利用率低、交换芯片难以线速转发的问题。
即时反馈
OISA支持即时反馈机制,允许发送端对满足条件的事务操作提前返回响应。在高并发场景中,可降低延迟,提前释放缓存资源,提高集群资源利用率。
智能感知
OISA支持一套高效的流量感知机制,实现GPU端侧与交换芯片侧协同,以对数据传输进行动态优化和数据反馈。使源端GPU能够获取数据传输路径上各个节点的状态信息,从而精确识别性能瓶颈点并调整发送策略,实现高效、无损的数据传输。
流量控制
OISA构建了一个确定性的无损网络,基于优先级的流量控制和缓存感知流量控制。这两种机制协同工作,能有效防止因互联拥塞导致的报文丢失,确保数据传输的稳定与可靠。
无损传输
OISA通过数据层重传机制,实现Scale-up域内的无损传输。当接收方检测到数据错误或丢失时,系统能立即启动点对点快速重传,保障数据在高带宽环境内的正确性和完整性。